Self-host LLM model
We take data security very seriously. Your code will sit on your premises and go to a model that you control, sitting in your cloud.
To self-host LLM model, you have two options:
Self-host using Amazon AWS
Self-host using Microsoft Azure
Both options are covered in detail below.
Pre-requisites
You will need access to a
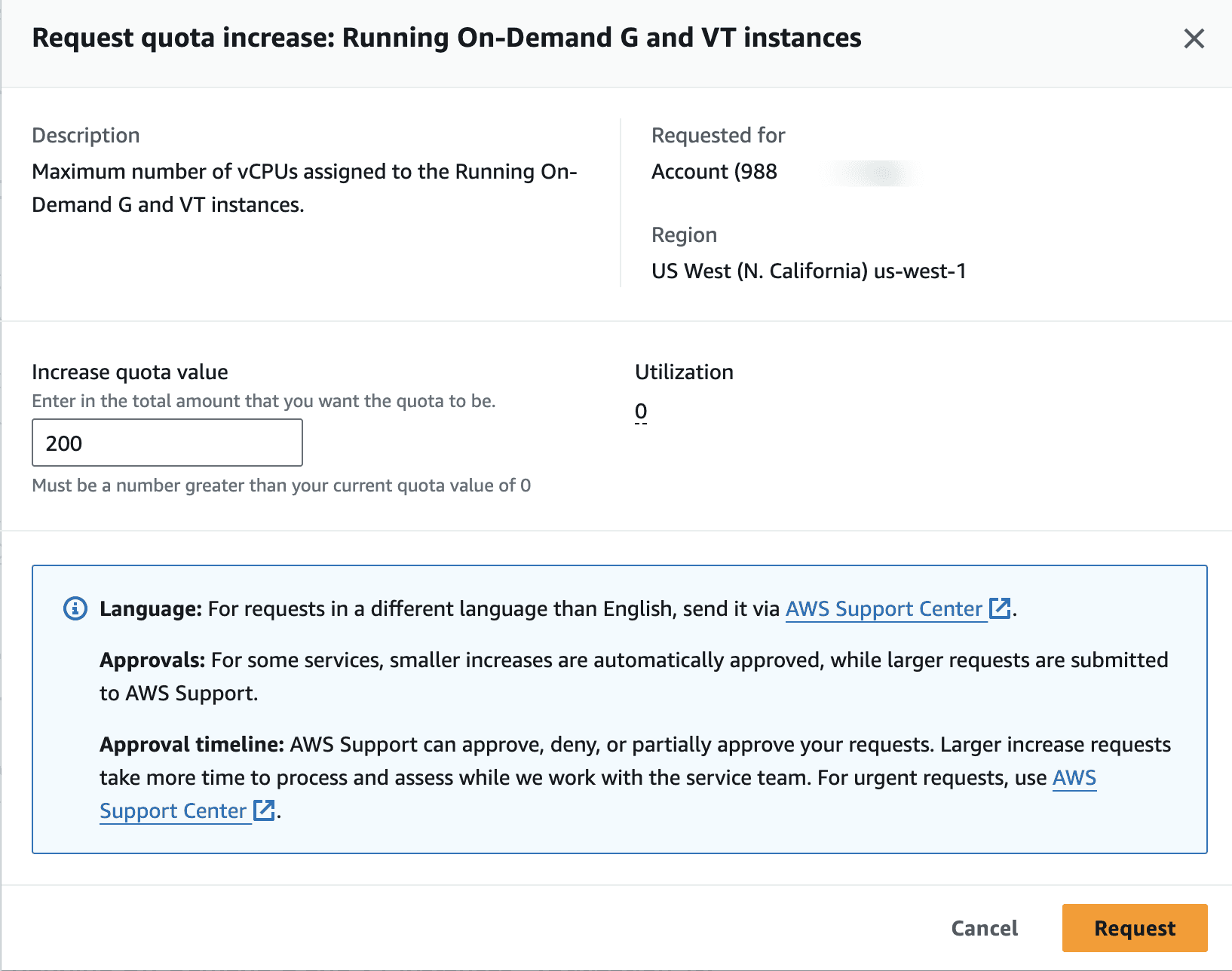
g5.48Xlarge instanceinstance. We runMixtral 8x7b Instruct v0.1, a large open source model.You will need to request a service quota increase. By going to the below link (make sure to change the region that is applicable to you):
https://<REGION_NAME>.console.aws.amazon.com/servicequotas/home/services/ec2/quotas/L-DB2E81BA
Click on
Request increase at account levelAsk for
200vcpus forIncrease quota valuefield
Alternatively, you can either leverage Bedrock (quicker to get set up), or you can negotiate with AWS to get access to this instance.
Setting up your LLM
Once you have access to the VCPUs, you need to create a new EC2 Instance.
Go to this link (make sure to change the region that is applicable to you): https://<REGION>.console.aws.amazon.com/ec2/home?region=<REGION>#LaunchInstances:
Name the Instance, for example
p0-llmClick on
Browse More AMIs
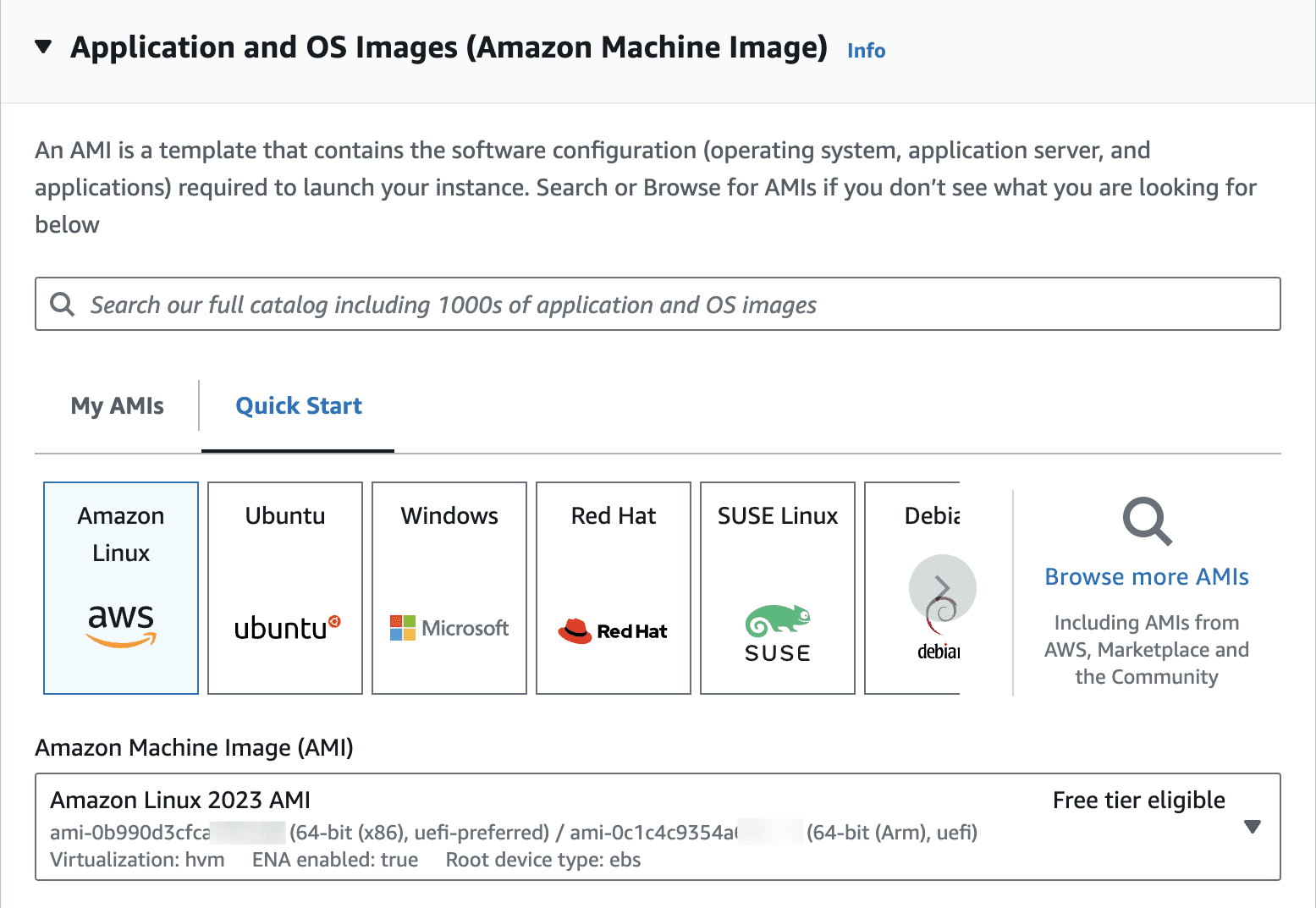
Click on
Community AMIsSearch for
P0-LLMPress
SelectSelect instance type as
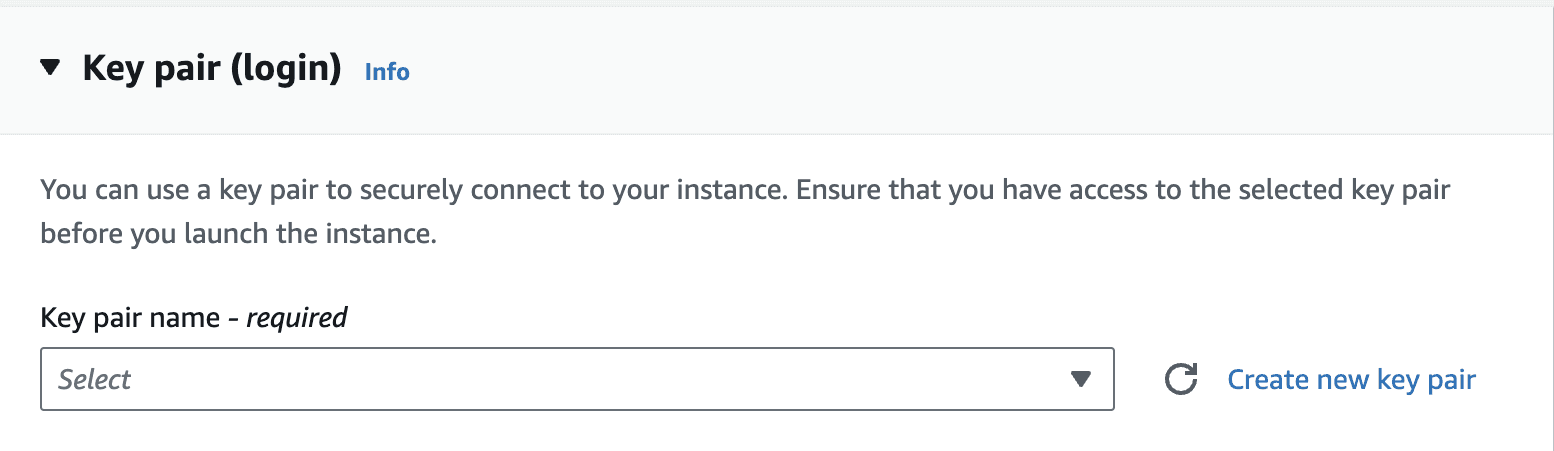
g5.48xLargeGenerate a key pair (or re-use an old one). Make sure you have access to this key pair.
Check
Allow HTTP traffic from the internetConfigure
350 GBof storage space.
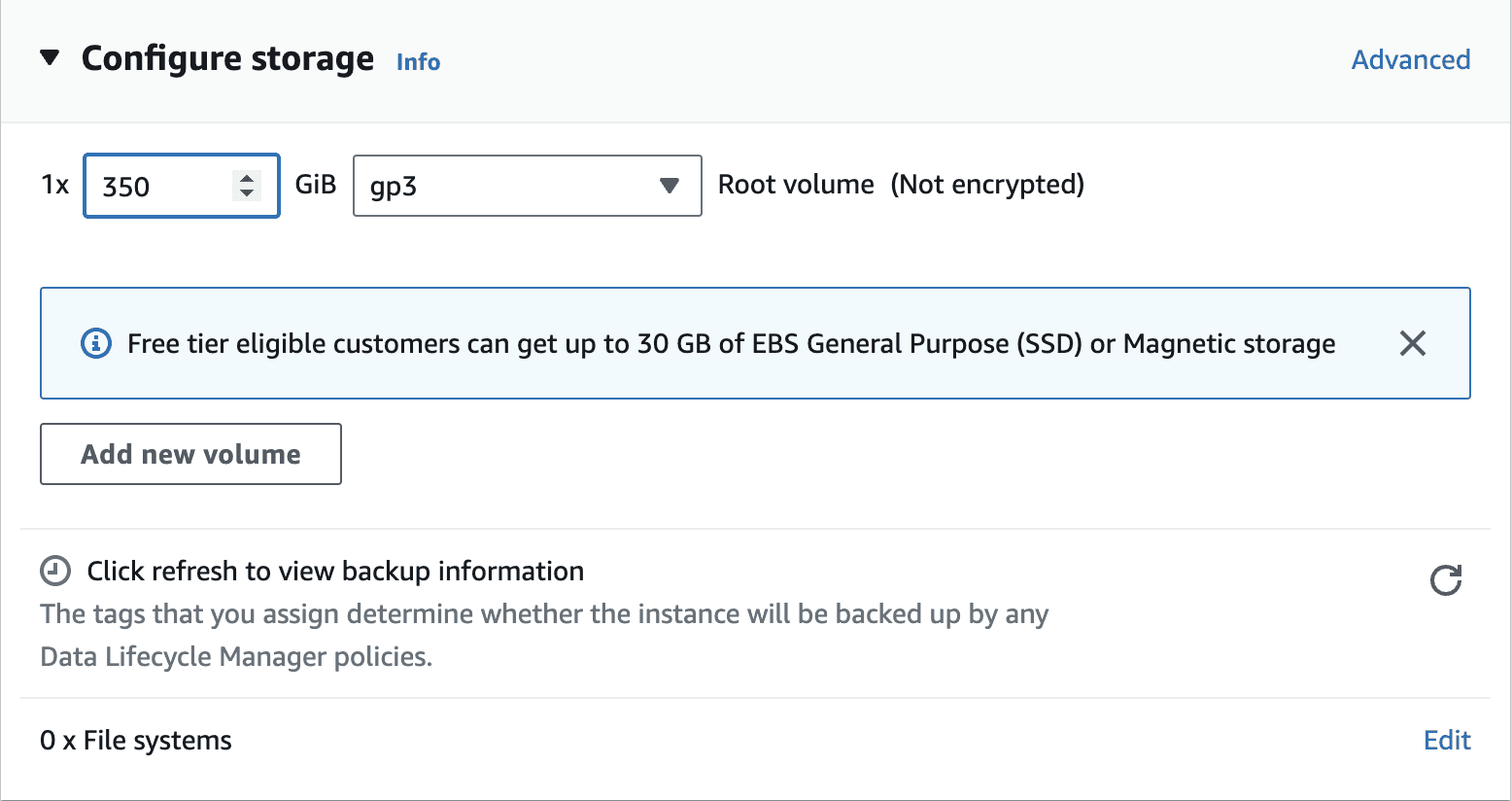
Make sure that the Instance is accessible from the EC2 box that runs the p0 service. Launch the instance.
Take note of the public Ipv4 address. You will need to paste this into the p0 product.

It may take up to 25 minutes to boot up the AMI completely. It takes some time for the LLM to stand up as it is quite large. You can check the reachability of the LLM by visiting http://<LLM_IP>/v1/chat/completions. This should result in the below (the “Method not Allowed” occurs because visiting the LLM in the browser has the wrong headers and payload)

Pre-requisites
You will need access to
Standard_NC96ads_A100_v4. We runMixtral 8x7b, a large open source model.First check to see if you have a quota in your region for the above instance. Go this link. Search for
NCADS_A100_v4. In the region of your choice change the limit to 96 vcpus.Then request the quota increase (you might have to create a support ticket for this as these GPUs are in short supply). If you cannot wait we recommend that you leverage Azure Pay-As-You-Go or Azure Hosted Endpoints, as these have no quotas associated with them.
Setting up your LLM
Once you have access to the VCPUs you will need to set up the LLM.
Go to this link
Create a new Resource Group (or use an existing one)
In Virtual Machine Name type in
P0-llmSet your desired region
Set one availability zone
Select the following:

In Size select the GPU instance you selected above.
Generate a new key pair or use an existing one. You will need to SSH into the GPU to be able to start it.

Configure
350 GBof disk space.Ensure that the LLM is accessible from the p0 server that you have set up before. If it is not accessible, the Scan will not work.
Press
Review + Create.Wait for the deployment to come up and press
Go to resource

Take note of the public IP. You will need this in to use the product.